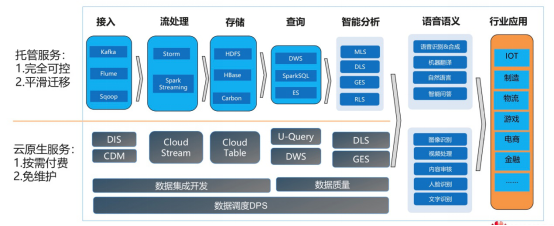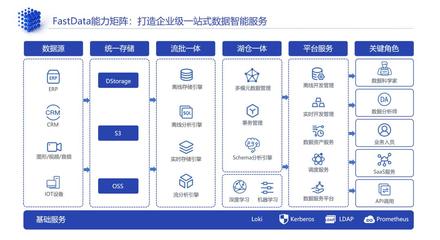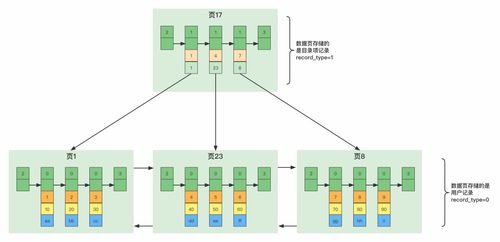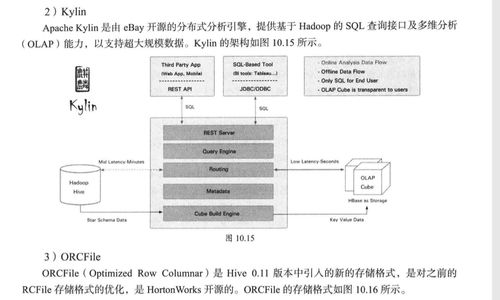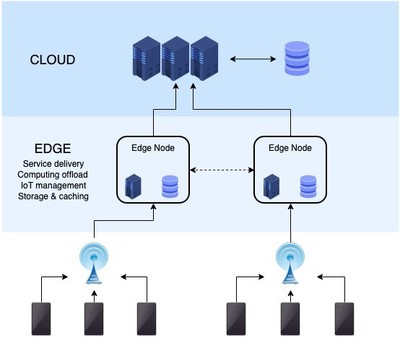
在物聯(lián)網(wǎng)邊緣計算架構(gòu)中,Kafka作為高吞吐量的分布式消息系統(tǒng),發(fā)揮了關(guān)鍵的數(shù)據(jù)處理和存儲作用。其核心優(yōu)勢包括高吞吐、低延遲和分布式架構(gòu),特別適合應(yīng)對物聯(lián)網(wǎng)設(shè)備產(chǎn)生的海量數(shù)據(jù)流。
Kafka在邊緣計算中的數(shù)據(jù)處理流程
- 數(shù)據(jù)采集與緩沖:邊緣設(shè)備通過Kafka生產(chǎn)者API將實時數(shù)據(jù)(如傳感器讀數(shù)、設(shè)備狀態(tài))發(fā)布到Kafka主題。Kafka的持久化日志結(jié)構(gòu)可作為數(shù)據(jù)緩沖區(qū),有效緩解網(wǎng)絡(luò)波動導(dǎo)致的數(shù)據(jù)丟失風(fēng)險。
- 流式處理集成:結(jié)合Kafka Streams或KSQL,可在邊緣節(jié)點直接實現(xiàn)數(shù)據(jù)過濾、聚合和轉(zhuǎn)換。例如對溫度傳感器數(shù)據(jù)實時計算移動平均值,僅將異常結(jié)果上傳至云端。
- 多級數(shù)據(jù)分發(fā):通過Kafka Connect將數(shù)據(jù)同步到邊緣數(shù)據(jù)庫(如SQLite)或云存儲(如S3),同時支持將關(guān)鍵數(shù)據(jù)轉(zhuǎn)發(fā)至云端Kafka集群進行深度分析。
存儲策略優(yōu)化
- 分層存儲配置:設(shè)置合理的日志保留策略,對實時數(shù)據(jù)保留24小時,重要數(shù)據(jù)通過壓縮主題長期存儲
- 數(shù)據(jù)序列化:采用Avro格式序列化數(shù)據(jù),結(jié)合Schema Registry確保邊緣與云端數(shù)據(jù)格式一致性
- 容災(zāi)機制:在邊緣網(wǎng)關(guān)部署Kafka鏡像節(jié)點,通過副本機制保障單點故障時的數(shù)據(jù)可用性
實踐案例參考
某智能制造企業(yè)在產(chǎn)線邊緣部署Kafka集群,每臺機床通過MQTT-Kafka橋接器上報運行參數(shù)。邊緣計算節(jié)點實時分析設(shè)備故障特征,當檢測到異常振動模式時,立即通過Kafka消息觸發(fā)本地告警,同時將精簡后的診斷數(shù)據(jù)批量上傳至云平臺。這種架構(gòu)使核心業(yè)務(wù)邏輯在邊緣完成,帶寬占用降低70%,故障響應(yīng)時間從秒級優(yōu)化至毫秒級。
注意事項
- 需根據(jù)邊緣設(shè)備資源限制調(diào)整Kafka內(nèi)存配置
- 建議使用輕量級Docker容器部署邊緣Kafka節(jié)點
- 通過TLS加密和SASL認證保障邊緣數(shù)據(jù)傳輸安全
通過合理運用Kafka的流處理能力和存儲特性,物聯(lián)網(wǎng)邊緣計算可構(gòu)建出兼具實時性、可靠性和可擴展性的數(shù)據(jù)處理體系。